



2019.12.05
検定(有意差検定)とは
検定(有意差検定)とは・・・ 調査により得られた結果の差異が『統計的』に違いがあるといえるのか?を判断する方法です。 例えば、2つの調査で男女のスコア差……



公開日:2022.10.31
多変量解析とは、複数データの関連性を分析することで、その関連性を要約したり、数値を予測するための解析作業の総称です。多変量解析は「たくさんのデータを組織的かつ論理的に調べる」ことを意味しており、データの要約・分類、データから予測する工程の総称を指します。
「売上や利益を上げるためには何をすれば良いのか?」。これは多くの企業が抱えている、永遠の課題とも言えます。「品質」「価格」「デザイン」「宣伝」「ブランド力」など、商品やサービスに求められる要素は数多くあります。
顧客は商品やサービスを購入する際、これら多くの要素を「バランス」良く考えて判断します。この「バランス」の中身は、とても複雑で抽象的です。そもそも、そのバランスを考えている私達自身が、「バランス」の内容を具体的には理解できていません。
一方で、顧客が持っているバランスには、ある程度の傾向があります。もし、このバランスの傾向を具体化できれば、企業はとても効率的なマーケティング戦略の立案や、顧客の購買行動予測ができるようになります。この「複雑なバランスを具体化する」統計的手法が「多変量解析」です。多変量解析を用いれば、これまで何となくでしか理解できなかったことを、具体的かつ分かりやすく把握できます。
ブランド認知度調査の調査票作成のポイント【テンプレート付】 無料ダウンロードはこちら>
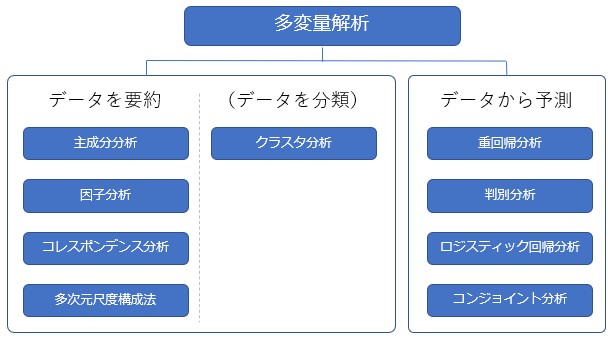
多変量解析の目的は、大量のデータを分析して、その関係性を「要約・分類」したり、関係性に基づいて「予測」することです。
「データの要約・分類」とは大量のデータを関係性の近さ(似ている/似ていない)でまとめて、視覚化する作業です。例えばアンケートなどでサンプルサイズや調査項目が多くなると、その関係を理解するのはとても大変な作業となります。
そのようなときに多変量解析を用いれば、アンケート結果の情報を歪めないようにしながら、回答者をグルーピングしたり、回答の傾向値を探ることができます。
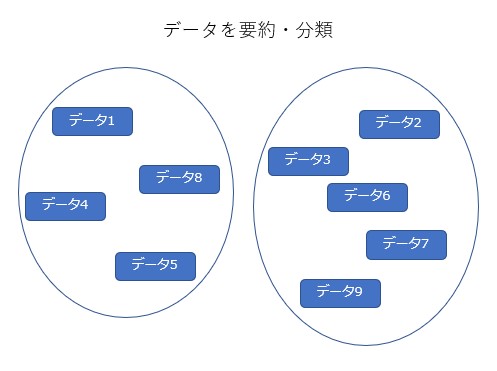
「データの予測」は大量のデータにどのような関係性があるかを調べて、その関係性に基づいてある状況での結果を推定する作業です。データの予測は大量のデータの中から、目的変数と呼ばれる予測する要素をピックアップします。その予測する要素(目的変数)が、その他の要素(説明変数)とどのような関係になっているかを分析し、その関係性を数式で表します。そうすると、その他の要素のデータを入力すれば、予測する要素がどのような数値になるかをある程度、予測できます。
多変量解析を上手に活用すると、マーケティング活動に有益な情報を把握できます。ここでは、その代表的な利用例を紹介します。
● アンケート結果から、ユーザーニーズに基づくグループ分けを行う。グループごとのユーザー特性(何を重視しているか)が分かるため、ターゲティングや具体的な対策を立てやすくなる。
● 自社商品の市場ポジションを明らかにして、自社の強みと弱みを把握する。その上で、今後、どのポイントを強化して競合との差別化を図るかを立案する。
● 既存店舗において「売上」とその他の要素の関係性を、数式として把握する。その数式に基づいて新規店舗の売上を予測し、事業計画に反映する。
● ネット通販で顧客が同時購入する商品の傾向を把握し、顧客に「おすすめ商品」を紹介する。
多変量解析では、4種類のデータを扱います。ここでは、そのデータについて解説します。
量的データとは、数値で表せるデータです。量的データには「間隔尺度」と「比例尺度」があります。
比例尺度
比例尺度とは金額、距離、時間など、絶対原点(基準点)があり、数値の比率に意味があるデータです。例えば、距離が10mと20mでは数値が2倍になれば、その絶対距離も2倍になったことを意味します。
質的データとは数値では表せない、もしくは計算結果に数値としての意味が見いだせないデータのことです。
順序尺度
1位、2位、3位のように順序や数値の大小には意味がありますが、数字の間隔が等しいとは限らない尺度のことです。例えば日本の歴代シングル売上では1位と2位の差は約132万枚、2位と3位の差は12万枚となるように順位差と売上差は大きく異なっています。
多変量解析は非常に便利な分析方法ですが、それを実施するためには必要な手順があります。ここではそれぞれの手順とその目的について解説します。
多変量解析には、その分析対象となるデータが必要です。また、そのデータは多変量解析を行う前提で集められたものでなければ、適切な結果が求められない場合があります。まずは、最終的にどのような結論を導き出したいかを検討し、その結果に基づいてアンケートなどでデータ収集を行います。
実は、良い分析結果を導き出すために、最も重要な作業がこのステップです。調査設計の段階でどれだけ有益な仮説を立てられるのか。また、その仮説に基づいてアンケート票を作成し、調査手法を決定するかどうかで調査結果の大部分が決まるといっても過言ではありません。ここで有益なデータを収集できなければ、その後のステップで挽回できることには限界があります。
もし、多変量解析を前提でデータ収集を行うのであれば、多変量解析に詳しい専門家に相談して、調査設計することをおすすめします。
単変量解析では1つずつの項目について解析します。この解析によって、不適切なデータの取り除き作業を行います。
異常値の処理
外れ値の中で、外れた理由が明確になったものが「異常値」です。例えば、先ほどの睡眠時間3時間の場合、回答者に確認したところ記入ミスが判明すれば異常値となります。異常値はその理由に応じて処理します。
ノイズの処理
回答の中で、数字記入欄に文字を書くなどの明らかな記載ミスが「ノイズ」です。ノイズは解析対象から外します。
2変量解析では2つの要素を組み合わせて、単変量解析では判明しなかった外れ値の抽出を行います。
例えば、平均客単価2000円のショップで、「1日売上30万円」「1日客数10人」というデータがあったとします。それぞれのデータ単体では外れ値ではなくても、「1日客数10人売上30万円」となれば、客単価は3万円となり平均客単価と比べると「外れ値」と考えられます。
このように2変量解析では2つのデータを組み合わせた散布図を作成し、一つの要素では分からなかった外れ値を調べます。外れ値の処理については、単変数解析と同様に処理します。
解析に不適切なデータをクリーニングした上で、多変量解析を行います。
多変量解析は、その目的に応じていくつかの種類があります。ここでは、それらの中で代表的な分析手法を紹介します。
● 主成分分析
複数の要素をまとめる分析方法。例として身長と体重から肥満度を示すBMIなど
● 多次元尺度構成法
類似しているデータを2次元あるいは3次元に配置して、視覚的に表現する分析方法。例としてポジショニングマップなど。
● クラスタ分析
混ざりあっている集団の中から互いに似ているものを集めてグループを作り分類するという方法。
● 因子分析
「ユーザー意識」「隠れたニーズ」など背後に潜んでいる要因を明らかにする分析手法。
● コレスポンデンス分析
2つの要素関係をクロス集計結果に基づいて散布図にする手法。
● 重回帰分析
ある結果(目的変数)を関連する複数の要素で数式化して将来の結果を予測する統計手法。例として、売上予測など。
● コンジョイント分析
複数の要素を持つ商品全体を評価してもらうことで、各要素がどのくらい商品全体の評価に影響を与えているのかを明らかにする分析方法。商品開発によく用いられる。
● 判別分析
過去のデータを元に分類基準をつくり、新しいデータがどの分類に該当するかを判別する手法。リピーター候補の判別など。
● ロジスティック回帰分析いくつかの要素から2値(Yes/No)が起こる確率を説明・予測することができる統計手法。例として、受験の合格可能性判定など。
● 数量化I・II・III類
調査項目をカテゴリーに分解してその一つ一つに適切なウエイトを計算して与える方法。「重回帰分析」に対応する「数量化I類」、「判別分析」に対応する「数量化 II 類」、「主成分分析」「因子分析」に対応する「数量化III類」がある。
多変量解析は大量のデータから関係を見出して、マーケティングに反映できる貴重な情報を把握できる優れた分析手法です。多変量解析をうまく用いれば、情報面において競合より優位に立ち、効果的なマーケティングの展開も充分に期待できます。
その一方で、効果的な多変量解析を行うには、高度な専門スキルと経験が要求されます。おそらく、相応のスキルを有しているプロフェッショナルがいない状態では、満足の得られる結果を導き出すのはかなり困難でしょう。
もし自社のマーケティングをレベルアップするために、多変量解析などデータ分析を検討されるのであれば、ぜひ専門家に相談されることをおすすめします。
市場調査についてのご相談はこちら>

クラスター分析で分かること|初めての方にも分かりやすく解説
初めての方でも理解できることを目指して、できるだけ難しい言葉を使わずクラスター分析の優れた点を分かりやすく解説しています。詳細はあまり気にしないで、大まかなイメージとしてクラスター分析を理解していきましょう。
> 詳しく見る
2019.12.05
検定(有意差検定)とは・・・ 調査により得られた結果の差異が『統計的』に違いがあるといえるのか?を判断する方法です。 例えば、2つの調査で男女のスコア差……
2024.04.26
コホート分析(コーホート分析)は、特定の条件でユーザーをグループに分け、その行動の時間経過に伴う変化を詳しく追跡し分析する方法です。この分析は、特にECサイトや……

2024.04.26
デモグラフィックデータは、個人や集団の人口統計学的特徴を示す情報で、年齢、性別、職業、居住地域、家族構成、年収などを含みます。この情報は、消費者の行動や好みを把……

2020.02.17
市場調査とは 市場調査とは、企業が行うマーケティング活動のためのあらゆる調査のことを言います。そのため、市場調査を理解する上で、その目的であるマーケティン……